HttpClient
- 2017 年 01 月 14 日
- Java
主要参考:
[1]http://www.cnblogs.com/loveyakamoz/archive/2011/07/21/2112804.html
[2]HttpClient 官方文档
HttpClient 教程
前沿
超文本传输协议(HTTP)也许是当今互联网上使用的最重要的协议了。 Web服务,有网络功能的设备和网络计算的发展,都持续扩展了HTTP协议的角色,超越了用户使用的Web浏览器范畴,同时,也增加了需要HTTP协议支持的应用程序的数量。
尽管java.net包提供了基本通过HTTP访问资源的功能,但它没有提供全面的灵活性和其它很多应用程序需要的功能。 HttpClient就是寻求弥补这项空白的组件,通过提供一个有效的,保持更新的,功能丰富的软件包来实现客户端最新的HTTP标准和建议。
为扩展而设计,同时为基本的HTTP协议提供强大的支持,HttpClient组件也许就是构建HTTP客户端应用程序,比如web浏览器,web服务端, 利用或扩展HTTP协议进行分布式通信的系统的开发人员的关注点。
1. HttpClient的范围
- 基于HttpCore http://hc.apache.org/httpcomponents-core/index.html 的客户端HTTP运输实现库
- 基于经典(阻塞)I/O
- 内容无关
2. 什么是HttpClient不能做的
- HttpClient不是一个浏览器。它是一个客户端的HTTP通信实现库。HttpClient的目标是发送和接收HTTP报文。 HttpClient不会去缓存内容,执行嵌入在HTML页面中的javascript代码,猜测内容类型,重新格式化请求/重定向URI,或者其它和HTTP运输无关的功能。
1. 基础
1.1 执行请求
HttpClient最重要的功能是执行HTTP方法。一个HTTP方法的执行包含一个或多个HTTP请求/HTTP响应交换,通常由HttpClient的内部来处理。 用户提供一个要执行的请求对象,而HttpClient传输请求对象到目标服务器并返回对应的响应对象,或者当执行不成功时抛出异常。
HttpClient API的主要切入点就是定义描述上述规约的HttpClient接口。
这里有一个很简单的请求执行过程的示例:
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpget = new HttpGet("http://localhost/");
CloseableHttpResponse response = httpclient.execute(httpget);
try {
//doSth();
} finally {
response.close();
}
1.1.1 Http request
所有HTTP请求都有一个由方法名、请求URI和HTTP协议版本组成的请求行。
HttpClient支持所有定义在HTTP/1.1版本中的HTTP方法:GET,HEAD,POST,PUT,DELETE,TRACE和OPTIONS。
对于每个方法类型都有一个特殊的类:HttpGet,HttpHead,HttpPost,HttpPut,HttpDelete,HttpTrace和HttpOptions。
请求的URI是统一资源定位符,它标识了请求应用于哪个资源。HTTP请求URI包含一个协议模式,主机名称,可选的端口,资源路径,可选的查询和可选的片段。
HttpGet httpget = new HttpGet("http://www.google.com/search?hl=en&q=httpclient&btnG=Google+Search&aq=f&oq=");
HttpClient提供很多工具方法来简化创建和修改执行URI。
URI uri = new URIBuilder()
.setScheme("http")
.setHost("www.google.com")
.setPath("/search")
.setParameter("q", "httpclient")
.setParameter("btnG", "Google Search")
.setParameter("aq", "f")
.setParameter("oq", "")
.build();
HttpGet httpget = new HttpGet(uri);
System.out.println(httpget.getURI());
输出:
http://www.google.com/search?q=httpclient&btnG=Google+Search&aq=f&oq=
1.1.2 Http response
HTTP响应是由服务器在接收和解释请求报文之后返回发送给客户端的报文。响应报文的第一行包含了协议版本,之后是数字状态码和相关联的文本段。
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
System.out.println(response.getProtocolVersion());
System.out.println(response.getStatusLine().getStatusCode());
System.out.println(response.getStatusLine().getReasonPhrase());
System.out.println(response.getStatusLine().toString());
输出:
HTTP/1.1
200
OK
HTTP/1.1 200 OK
1.1.3 处理报文头
一个HTTP报文可以包含很多描述如内容长度,内容类型等信息属性的头部信息。HttpClient提供获取,添加,移除和枚举头部信息的方法。
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
response.addHeader("Set-Cookie", "c1=a; path=/; domain=localhost");
response.addHeader("Set-Cookie", "c2=b; path=\"/\", c3=c; domain=\"localhost\"");
Header h1 = response.getFirstHeader("Set-Cookie");
System.out.println(h1);
Header h2 = response.getLastHeader("Set-Cookie");
System.out.println(h2);
Header[] hs = response.getHeaders("Set-Cookie");
System.out.println(hs.length);
输出:
Set-Cookie: c1=a; path=/; domain=localhost
Set-Cookie: c2=b; path="/", c3=c; domain="localhost"
2
获得给定类型的所有头部信息最有效的方式是使用HeaderIterator.
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
response.addHeader("Set-Cookie", "c1=a; path=/; domain=localhost");
response.addHeader("Set-Cookie", "c2=b; path=\"/\", c3=c; domain=\"localhost\"");
HeaderIterator it = response.headerIterator("Set-Cookie");
while (it.hasNext()) {
System.out.println(it.next());
}
输出:
Set-Cookie: c1=a; path=/; domain=localhost
Set-Cookie: c2=b; path="/", c3=c; domain="localhost"
它也提供解析HTTP报文到独立头部信息元素的方法
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK, "OK");
response.addHeader("Set-Cookie", "c1=a; path=/; domain=localhost");
response.addHeader("Set-Cookie", "c2=b; path=\"/\", c3=c; domain=\"localhost\"");
HeaderElementIterator it = new BasicHeaderElementIterator(response.headerIterator("Set-Cookie"));
while (it.hasNext()) {
HeaderElement elem = it.nextElement();
System.out.println(elem.getName() + " = " + elem.getValue());
NameValuePair[] params = elem.getParameters();
for (int i = 0; i < params.length; i++) {
System.out.println(" " + params[i]);
}
}
输出:
c1 = a
path=/
domain=localhost
c2 = b
path=/
c3 = c
domain=localhost
1.1.4 Http Entity
HTTP报文可以携带和request或response相关的内容实体。实体可以在一些请求和响应中找到,因为它们也是可选的。使用了实体的请求被称为封闭实体请求。
HTTP规范定义了两种封闭实体的方法:POST和PUT。响应通常期望包含一个内容实体。
这个规则也有特例,比如HEAD方法的响应和204 No Content,304 Not Modified和205 Reset Content响应。
HttpClient根据其内容出自何处区分三种类型的实体:
- streamed流式:内容从流中获得,或者在运行中产生。特别是这种分类包含从HTTP响应中获取的实体。流式实体是不可重复生成的。
- self-contained自我包含式:内容在内存中或通过独立的连接或其它实体中获得。自我包含式的实体是可以重复生成的。这种类型的实体会经常用于封闭HTTP请求的实体。
- wrapping包装式:内容从另外一个实体中获得。
1.1.4.1 Repeatable entities
实体可以重复,意味着它的内容可以被多次读取。这就仅仅是自我包含式的实体了(像ByteArrayEntity或StringEntity)。
1.1.4.2 使用http实体
因为一个实体既可以代表二进制内容又可以代表字符内容,它也支持字符编码(支持后者也就是字符内容)。
实体是当使用封闭内容执行请求,或当请求已经成功执行,或当响应体结果发功到客户端时创建的。
要从实体中读取内容,可以通过HttpEntity#getContent()方法从输入流中获取,这会返回一个java.io.InputStream对象,
或者提供一个输出流到HttpEntity#writeTo(OutputStream)方法中,这会一次返回所有写入到给定流中的内容。
当实体通过一个收到的报文获取时,HttpEntity#getContentType()方法和HttpEntity#getContentLength()方法可以用来读取通用的元数据,如Content-Type和Content-Length头部信息(如果它们是可用的)。
因为头部信息Content-Type可以包含对文本MIME类型的字符编码,比如text/plain或text/html,HttpEntity#getContentEncoding()方法用来读取这个信息。
如果头部信息不可用,那么就返回长度-1,而内容类型返回NULL。如果头部信息Content-Type是可用的,那么就会返回一个Header对象。
当为一个传出报文创建实体时,这个元数据不得不通过实体创建器来提供。
StringEntity myEntity = new StringEntity("important message", ContentType.create("text/plain", "UTF-8"));
System.out.println(myEntity.getContentType());
System.out.println(myEntity.getContentLength());
System.out.println(EntityUtils.toString(myEntity));
System.out.println(EntityUtils.toByteArray(myEntity).length);
输出:
Content-Type: text/plain; charset=UTF-8
17
important message
17
1.1.5 确保低级别资源释放
为了确保正确释放系统资源,Entity的content stream以及response都应该显示关闭.
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpget = new HttpGet("http://localhost/");
CloseableHttpResponse response = httpclient.execute(httpget);
try {
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream instream = entity.getContent();
try {
// do something useful
} finally {
instream.close();
}
}
} finally {
response.close();
}
关闭content stream和关闭response的区别:
former will attempt to keep the underlying connection alive by consuming the entity content while the latter immediately shuts down and discards the connection.
Call
HttpEntity#writeTo(OutputStream)和HttpEntity#getContent()都需要正确关闭系统资源. 使用streaming entities时,可以CallEntityUtils#consume(HttpEntity)方法可以确保完全消费entity content和关闭steam.
也可能会有特殊情况,当整个响应内容的一小部分需要获取,消耗剩余内容而损失性能,还有重用连接的代价太高,则可以仅仅通过关闭response。
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpget = new HttpGet("http://localhost/");
CloseableHttpResponse response = httpclient.execute(httpget);
try {
HttpEntity entity = response.getEntity();
if (entity != null) {
InputStream instream = entity.getContent();
int byteOne = instream.read();
int byteTwo = instream.read();
// Do not need the rest
}
} finally {
response.close();
}
连接不会被重用,但是由它持有的所有级别的资源将会被正确释放。
1.1.6 Consuming entity content
推荐消耗实体内容的方式是使用它的HttpEntity#getContent()或HttpEntity#writeTo(OutputStream)方法。
HttpClient也自带EntityUtils类,这会暴露出一些静态方法,这些方法可以更加容易地从实体中读取内容或信息。
然而,EntityUtils的使用是强烈不推荐的,除非响应实体源自可靠的HTTP服务器和已知的长度限制。
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpget = new HttpGet("http://localhost/");
CloseableHttpResponse response = httpclient.execute(httpget);
try {
HttpEntity entity = response.getEntity();
if (entity != null) {
long len = entity.getContentLength();
if (len != -1 && len < 2048) {
System.out.println(EntityUtils.toString(entity));
} else {
// Stream content out
}
}
} finally {
response.close();
}
在一些情况下可能会不止一次的读取实体。此时实体内容必须以某种方式在内存或磁盘上被缓冲起来。
最简单的方法是通过使用BufferedHttpEntity类来包装源实体完成。
CloseableHttpResponse response = <...>
HttpEntity entity = response.getEntity();
if (entity != null) {
entity = new BufferedHttpEntity(entity);
}
1.1.7 Producing entity content
为了把entity封装在request里面,HttpClient为很多公用的数据容器,比如字符串,字节数组,输入流和文件提供了一些类:StringEntity,ByteArrayEntity,InputStreamEntity和FileEntity。
File file = new File("somefile.txt");
FileEntity entity = new FileEntity(file, ContentType.create("text/plain", "UTF-8"));
HttpPost httppost = new HttpPost("http://localhost/action.do");
httppost.setEntity(entity);
##### 1.1.7.1 HTML 表单
许多应用程序需要频繁模拟提交一个HTML表单的过程,比如,为了来记录一个Web应用程序或提交输出数据。
为此,HttpClient提供了特殊的实体类UrlEncodedFormEntity。
List<NameValuePair> formparams = new ArrayList<NameValuePair>();
formparams.add(new BasicNameValuePair("param1", "value1"));
formparams.add(new BasicNameValuePair("param2", "value2"));
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(formparams, Consts.UTF_8);
HttpPost httppost = new HttpPost("http://localhost/handler.do");
httppost.setEntity(entity);
UrlEncodedFormEntity实例将会使用URL编码来编码参数,生成如下的内容:
param1=value1¶m2=value2
1.1.7.2 Content chunking
通常,我们推荐让HttpClient选择基于被传递的HTTP报文属性的最适合的编码转换。
这是可能的,但是,设置HttpEntity#setChunked()方法为true是通知HttpClient分块编码的首选。
请注意HttpClient将会使用标识作为hint。当使用的HTTP协议版本不支持分块编码时,如HTTP/1.0版本,这个值会被忽略。
StringEntity entity = new StringEntity("important message",
ContentType.create("plain/text", Consts.UTF_8));
entity.setChunked(true);
HttpPost httppost = new HttpPost("http://localhost/acrtion.do");
httppost.setEntity(entity);
1.1.8 response handlers
处理response最简便和最方便的方式是使用ResponseHandler接口(包含方法handleResponse(HttpResponse response))。
这个方法完全减轻了用户关于连接管理的担心。
当使用ResponseHandler时,HttpClient将会自动关注并保证释放连接到连接管理器中去,而不管请求执行是否成功或引发了异常。
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpGet httpget = new HttpGet("http://localhost/json");
ResponseHandler<MyJsonObject> rh = new ResponseHandler<MyJsonObject>() {
@Override
public JsonObject handleResponse(final HttpResponse response) throws IOException {
StatusLine statusLine = response.getStatusLine();
HttpEntity entity = response.getEntity();
if (statusLine.getStatusCode() >= 300) {
throw new HttpResponseException(statusLine.getStatusCode(), statusLine.getReasonPhrase());
}
if (entity == null) {
throw new ClientProtocolException("Response contains no content");
}
Gson gson = new GsonBuilder().create();
ContentType contentType = ContentType.getOrDefault(entity);
Charset charset = contentType.getCharset();
Reader reader = new InputStreamReader(entity.getContent(), charset);
return gson.fromJson(reader, MyJsonObject.class);
}
};
MyJsonObject myjson = client.execute(httpget, rh);
1.2 HttpClient interface
HttpClient接口代表了最重要的HTTP请求执行的契约。 它没有在请求执行处理上强加限制或特殊细节,而在连接管理,状态管理,认证和处理重定向到具体实现上留下了细节。 这应该使得使用额外的功能来装饰接口很容易,比如响应内容缓存。
Generally HttpClient implementations act as a facade to a number of special purpose handler or strategy interface implementations responsible for handling of a particular aspect of the HTTP protocol such as redirect or authentication handling or making decision about connection persistence and keep alive duration. This enables the users to selectively replace default implementation of those aspects with custom, application specific ones.
ConnectionKeepAliveStrategy keepAliveStrat = new DefaultConnectionKeepAliveStrategy() {
@Override
public long getKeepAliveDuration(HttpResponse response, HttpContext context) {
long keepAlive = super.getKeepAliveDuration(response, context);
if (keepAlive == -1) {
// Keep connections alive 5 seconds if a keep-alive value
// has not be explicitly set by the server
keepAlive = 5000;
}
return keepAlive;
}
};
CloseableHttpClient httpclient = HttpClients.custom().setKeepAliveStrategy(keepAliveStrat).build();
1.2.1 HttpClient thread safety
HttpClient implementations are expected to be thread safe. It is recommended that the same instance of this class is reused for multiple request executions.
1.2.2 HttpClient resource deallocation
一个CloseableHttpClient示例不再需要,或将要走出connection manager的作用域的时候,必须要通过CloseableHttpClient#close()关闭.
CloseableHttpClient httpclient = HttpClients.createDefault();
try {
<...>
} finally {
httpclient.close();
}
1.3 HTTP execution context
最初,HTTP是被设计成无状态的,面向请求-响应的协议。
然而,真实的应用程序经常需要通过一些逻辑相关的请求-响应交换来持久状态信息。
为了能使应用程序来维持一个过程状态,HttpClient允许HTTP请求在一个特定的执行环境中来执行,简称为HTTP上下文。
如果相同的环境在连续请求之间能够重用,那么多种逻辑相关的请求可以参与到一个逻辑会话中。
HTTP上下文功能和java.util.Map<String,Object>很相似。
它仅仅是任意命名参数值的集合。
应用程序可以在请求之前或在检查上下文执行完成之后来填充上下文属性。
HttpContext能够包含任意的对象,所以在多个线程中共享是不安全的。因此,要求每个线程都维护自己的上下文。
在HTTP请求执行的这一过程中,HttpClient添加了下列属性到执行上下文中:
HttpConnection:连接到目标服务器的真实连接.HttpHost:连接目标.HttpRoute:完整的connection route.HttpRequest:真实的HTTP请求. 执行上下中,最终的HttpRequest对象总是精确代表了待发送到目标服务器的消息的状态. HTTP/1.0 and HTTP/1.1默认使用relative request URIs. 然而,如果request是通过non-tunneling的代理,URI是absolute的.HttpResponse:真实的HTTP响应.java.lang.Boolean:标识request是否完全被传送到目标连接。RequestConfig:active request configuation.java.util.List<URI>: 代表了request请求执行过程中,所有重定向位置的集合.
可以通过HttpClientContext适配器类来简化获取这些状态.
HttpContext context = <...>
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpHost target = clientContext.getTargetHost();
HttpRequest request = clientContext.getRequest();
HttpResponse response = clientContext.getResponse();
RequestConfig config = clientContext.getRequestConfig();
一个逻辑相关的session中的多个request序列,具有相同的HttpContext实例,这保证了在多个request中能够正确传播会话内容和状态信息.
In the following example the request configuration set by the initial request will be kept in the execution context and get propagated to the consecutive requests sharing the same context.
CloseableHttpClient httpclient = HttpClients.createDefault();
RequestConfig requestConfig = RequestConfig.custom().setSocketTimeout(1000).setConnectTimeout(1000).build();
HttpGet httpget1 = new HttpGet("http://localhost/1");
httpget1.setConfig(requestConfig);
CloseableHttpResponse response1 = httpclient.execute(httpget1, context);
try {
HttpEntity entity1 = response1.getEntity();
} finally {
response1.close();
}
HttpGet httpget2 = new HttpGet("http://localhost/2");
CloseableHttpResponse response2 = httpclient.execute(httpget2, context);
try {
HttpEntity entity2 = response2.getEntity();
} finally {
response2.close();
}
1.4 HTTP protocol interceptors
HTTP协议拦截器是一个实现了特定HTPP协议方面的惯例。 通常协议拦截器希望作用于一个特定头部信息上,或者一族收到报文的相关头部信息,或使用一个特定的头部或一族相关的头部信息填充发出的报文。 协议拦截器也可以操纵包含在报文中的内容实体,透明的内容压缩/解压就是一个很好的示例。 通常情况下这是由包装器实体类使用了“装饰者”模式来装饰原始的实体完成的。 一些协议拦截器可以从一个逻辑单元中来结合。
协议拦截器也可以通过共享信息来共同合作-比如处理状态-通过HTTP执行上下文。 协议拦截器可以使用HTTP内容来为一个或多个连续的请求存储一个处理状态。
通常拦截器执行的顺序不应该和它们基于的特定执行上下文状态有关。 如果协议拦截器有相互依存关系,那么它们必须按特定顺序来执行,正如它们希望执行的顺序一样,它们应该在相同的序列中被加到协议处理器。
协议拦截器必须实现为线程安全的。和Servlet相似,协议拦截器不应该使用实例变量,除非访问的那些变量是同步的。
这个示例给出了本地内容在连续的请求中怎么被用于持久一个处理状态的:
CloseableHttpClient httpclient = HttpClients.custom().addInterceptorLast(new HttpRequestInterceptor() {
public void process(final HttpRequest request, final HttpContext context) throws HttpException, IOException {
AtomicInteger count = (AtomicInteger) context.getAttribute("count");
request.addHeader("Count", Integer.toString(count.getAndIncrement()));
}
}).build();
AtomicInteger count = new AtomicInteger(1);
HttpClientContext localContext = HttpClientContext.create();
localContext.setAttribute("count", count);
HttpGet httpget = new HttpGet("http://localhost/");
for (int i = 0; i < 10; i++) {
CloseableHttpResponse response = httpclient.execute(httpget, localContext);
try {
HttpEntity entity = response.getEntity();
} finally {
response.close();
}
}
1.5 Exception handling
HttpClient能够抛出两种类型的异常:在I/O失败时,如套接字连接超时或被重置的java.io.IOException异常,
还有标志HTTP请求失败的信号,如违反HTTP协议的HttpException异常。
通常I/O错误被认为是非致命的和可以恢复的,而HTTP协议错误则被认为是致命的而且是不能自动恢复的。
注意,HttpClient中使用的ClientProtocolException继承自java.io.IOException.
1.5.1 HTTP transport safety
要理解HTTP协议并不是对所有类型的应用程序都适合的,这一点很重要。 HTTP是一个简单的面向请求/响应的协议,最初被设计用来支持取回静态或动态生成的内容。 它从未向支持事务性操作方向发展。 比如,如果成功收到和处理请求,HTTP服务器将会考虑它的其中一部分是否完成,生成一个响应并发送一个状态码到客户端。 如果客户端因为读取超时,请求取消或系统崩溃导致接收响应实体失败时,服务器不会试图回滚事务。 如果客户端决定重新这个请求,那么服务器将不可避免地不止一次执行这个相同的事务。 在一些情况下,这会导致应用数据损坏或者不一致的应用程序状态。
尽管HTTP从来都没有被设计来支持事务性处理,但它也能被用作于一个传输协议对关键的任务应用提供被满足的确定状态。 要保证HTTP传输层的安全,系统必须保证HTTP方法在应用层的幂等性。
1.5.2 Idempotent methods
HTTP/1.1 明确地定义了幂等的方法,描述如下
[方法也可以有“幂等”属性在那些(除了错误或过期问题)N的副作用>0的相同请求和独立的请求是相同的] 换句话说,应用程序应该保证准备着来处理多个相同方法执行的实现。这是可以达到的,比如,通过提供一个独立的事务ID和其它避免执行相同逻辑操作的方法。
请注意这个问题对于HttpClient是不具体的。基于应用的浏览器特别受和非幂等的HTTP方法相关的相同问题的限制。 HttpClient假设没有实体包含方法,比如GET和HEAD是幂等的,而实体包含方法,比如POST和PUT则不是。
1.5.3 Automatic exception recovery
默认情况下,HttpClient会试图自动从I/O异常中恢复。默认的自动恢复机制是受很少一部分已知的异常是安全的这个限制。
- HttpClient不会从任意逻辑或HTTP协议错误(那些是从HttpException类中派生出的)中恢复的。
- HttpClient将会自动重新执行那么假设是幂等的方法。
- HttpClient将会自动重新执行那些由于运输异常失败,而HTTP请求仍然被传送到目标服务器(也就是请求没有完全被送到服务器)失败的方法。
- HttpClient将会自动重新执行那些已经完全被送到服务器,但是服务器使用HTTP状态码(服务器仅仅丢掉连接而不会发回任何东西)响应时失败的方法。 在这种情况下,假设请求没有被服务器处理,而应用程序的状态也没有改变。 如果这个假设可能对于你应用程序的目标Web服务器来说不正确,那么就强烈建议提供一个自定义的异常处理器。
1.5.4 Request retry handler
为了开启自定义异常恢复机制,应该提供一个HttpRequestRetryHandler接口的实现。
HttpRequestRetryHandler myRetryHandler = new HttpRequestRetryHandler() {
public boolean retryRequest(IOException exception, int executionCount, HttpContext context) {
if (executionCount >= 5) {
// Do not retry if over max retry count
return false;
}
if (exception instanceof InterruptedIOException) {
// Timeout
return false;
}
if (exception instanceof UnknownHostException) {
// Unknown host
return false;
}
if (exception instanceof ConnectTimeoutException) {
// Connection refused
return false;
}
if (exception instanceof SSLException) {
// SSL handshake exception
return false;
}
HttpClientContext clientContext = HttpClientContext.adapt(context);
HttpRequest request = clientContext.getRequest();
boolean idempotent = !(request instanceof HttpEntityEnclosingRequest);
if (idempotent) {
// Retry if the request is considered idempotent
return true;
}
return false;
}
};
CloseableHttpClient httpclient = HttpClients.custom().setRetryHandler(myRetryHandler).build();
Please note that one can use StandardHttpRequestRetryHandler instead of the one used by default in
order to treat those request methods defined as idempotent by RFC-2616 as safe to retry automatically:
GET, HEAD, PUT, DELETE, OPTIONS, and TRACE.
1.6 Aborting requests
在一些情况下,由于目标服务器的高负载或客户端有很多活动的请求,那么HTTP请求执行会在预期的时间框内而失败。
这时,就可能不得不过早地中止请求,解除封锁在I/O执行中的线程封锁。
被HttpClient执行的HTTP请求可以在执行的任意阶段通过调用HttpUriRequest#abort()方法而中止。
这个方法是线程安全的,而且可以从任意线程中调用。
当一个HTTP请求被中止时,它的执行线程就封锁在I/O操作中了,而且保证通过抛出InterruptedIOException异常来解锁。
1.7 Redirect handling
HttpClient handles all types of redirects automatically, except those explicitly prohibited by the HTTP specification as requiring user intervention. See Other (status code 303) redirects on POST and PUT requests are converted to GET requests as required by the HTTP specification. One can use a custom redirect strategy to relaxe restrictions on automatic redirection of POST methods imposed by the HTTP specification.
LaxRedirectStrategy redirectStrategy = new LaxRedirectStrategy();
CloseableHttpClient httpclient = HttpClients.custom().setRedirectStrategy(redirectStrategy).build();
HttpClient often has to rewrite the request message in the process of its execution. Per default HTTP/1.0 and HTTP/1.1 generally use relative request URIs. Likewise, original request may get redirected from location to another multiple times. The final interpreted absolute HTTP location can be built using the original request and the context. The utility method URIUtils#resolve can be used to build the interpreted absolute URI used to generate the final request. This method includes the last fragment identifier from the redirect requests or the original request.
CloseableHttpClient httpclient = HttpClients.createDefault();
HttpClientContext context = HttpClientContext.create();
HttpGet httpget = new HttpGet("http://localhost:8080/");
CloseableHttpResponse response = httpclient.execute(httpget, context);
try {
HttpHost target = context.getTargetHost();
List<URI> redirectLocations = context.getRedirectLocations();
URI location = URIUtils.resolve(httpget.getURI(), target, redirectLocations);
System.out.println("Final HTTP location: " + location.toASCIIString());
// Expected to be an absolute URI
} finally {
response.close();
}
java 闭包
- 2017 年 01 月 04 日
- Java
1. 闭包
不严谨的说法:
- 一个与外部环境自由变量的函数
- 这个函数能访问外部环境里的自由变量
javascript中的闭包例子:
function add(y) {
return function(x) {
return x + y;
}
}
对于内部函数function(x) 来说: 1. y是自由变量 2. 其返回值依赖于外部自由变量y 3. add(y) 正好是包含y的环境. 此时,外部函数add(y)对内部函数function(x)形成了闭包.
2. java中的闭包
2.1 类和对象
class Add {
private int x = 1;
public int add() {
int y = 2;
return x + y;
}
}
变量x在add() 外部,add() 方法中通过this关键字访问x. 对象即是闭包.
2.2 内部类
public class Outer {
private int x = 100;
class Inner {
private int y = 1;
public int innerAdd() {
return x + y;
}
}
}
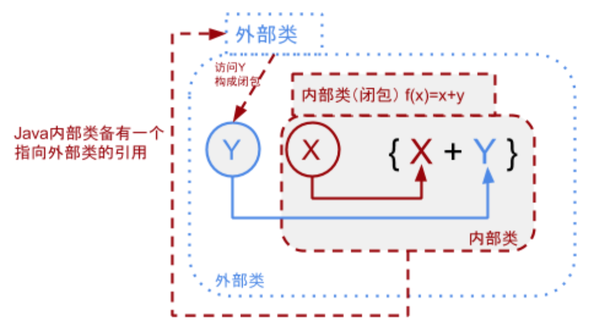
内部类通过包含一个指向外部类的引用,做到自由访问外部类的所有字段,变相的把环境中的自由变量封装到函数里,形成一个闭包.
内部类闭包示意图:
2.3 匿名内部类
class Outer {
public AnnoInner getAnnoInner(final int x) {
final int y = 2;
return new AnnoInner() {
@Override
public int addXYZ() {
int z = 3;
return x + y + z;
}
};
}
}
getAnnoInner() 对内部匿名类构成了一个闭包. 但这里别扭的地方是这两个x和y都必须用final修饰,不可以修改。 这是为什么呢?因为这里Java编译器对闭包的支持不完整。说支持了闭包,是因为编译器编译的时候其实悄悄对函数做了手脚,偷偷把外部环境方法的x和y局部变量,拷贝了一份到匿名内部类里。
Java编译器实现的只是capture-by-value,并没有实现capture-by-reference。
而只有后者才能保持匿名内部类和外部环境局部变量保持同步。 内部类会自动拷贝外部变量的引用,为了避免:1. 外部方法修改引用,而导致内部类得到的引用值不一致 2.内部类修改引用,而导致外部方法的参数值在修改前和修改后不一致。于是就用 final 来让该引用不可改变。 为了同步,Java就不许大家改外围的局部变量。
2.4 其他和匿名内部类相似的情况
除了匿名内部类,还有几种情况,来自外部闭包环境的自由变量必须是final的。
a. 在外部类成员方法中的内部类.
class Outer {
public void function(final int x) {
final int y = 2;
class MethodInner {
public int add() {
int z = 3;
return x + y;
}
}
}
}
b. 在一个代码块block里的内部类.
class Outer {
private int x = 0;
{
final int y = 2;
class MethodInner {
public int add() {
int z = 3;
return x + y;
}
}
}
}
fetch data from database
- 2016 年 12 月 26 日
- Java
oracle导出数据至csv
public class ExportDataToCSV {
private static final String SEPARATOR = ",";
private static final int FETCH_SIZE = 10000;
public void export(String tableName) {
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
File file = new File(tableName + ".csv");
if (file.exists() && !file.delete()) {
throw new RuntimeException("delete file failed");
}
connection = DBManager4Oracle.getConnection(); //get connection
connection.setAutoCommit(false);
statement = connection.createStatement();
statement.setFetchSize(FETCH_SIZE);
resultSet = statement.executeQuery(String.format("select * from %1$s", tableName));
processSearchResult(resultSet, file);
} catch (Exception e) {
throw new RuntimeException("fail", e);
} finally {// close resource
DBManager.closeStatement(statement, resultSet);
DBManager.releaseConnection(connection);
}
}
private void processSearchResult(ResultSet resultSet, File file) throws SQLException, FileNotFoundException {
PrintWriter printWriter = null;
try {
printWriter = new PrintWriter(new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file))));
int size = writeFileHead(resultSet, printWriter);
writeFileBody(resultSet, printWriter, size);
} finally {
if (printWriter != null) {
printWriter.close();
}
}
}
private void writeFileBody(ResultSet resultSet, PrintWriter printWriter, int size) throws SQLException {
List<String> dataList = new ArrayList<String>(size);
while (resultSet.next()) {
for (int i = 1; i <= size; i++) {
Object object = resultSet.getObject(i);
dataList.add(object == null ? "" : object.toString());
}
printWriter.println(convertListToString(dataList));
dataList.clear();
}
}
private int writeFileHead(ResultSet resultSet, PrintWriter printWriter) throws SQLException {
ResultSetMetaData metaData = resultSet.getMetaData();
int size = metaData.getColumnCount();
if (size == 0)
throw new RuntimeException("cannot find any column");
List<String> columnList = new ArrayList<String>(size);
for (int i = 1; i <= size; i++) {
columnList.add(metaData.getColumnName(i));
}
printWriter.println(convertListToString(columnList));
return size;
}
private String convertListToString(List<String> dataList) {
StringBuilder stringBuilder = new StringBuilder();
for (String data : dataList) {
stringBuilder.append(SEPARATOR).append("\"").append(data).append("\"");
}
return stringBuilder.substring(1);
}
public static void main(String[] args) {
ExportDataToCSV export = new ExportDataToCSV();
export.export("student");
}
}
Thinking in Java - Exception
- 2016 年 10 月 19 日
- Java
异常
异常的限制
-
当子类覆盖父类方法时,只能抛出在父类方法的异常说明中列出的那些异常。但是此限制对构造器函数不起作用,子类构造器的异常说明必须包含父类构造器中的异常说明。
-
子类构造器不能catch基类构造器抛出的异常。
-
只针对异常的情况下才使用异常,永远不要把异常用于正常的控制流。
-
对可恢复的情况使用受检异常,对编程错误使用运行时异常。
oracle 优化
- 2016 年 10 月 19 日
- oralce
1. 单表查询
1.1 空值转换成实际值
select coalesce(col, value) from dual;
coalesce 比NVL高级,支持多个col, 如 coalesce(col1, col2, value);
1.2 case when
SELECT T.SALARY, (CASE WHEN T.SALARY < 4000 THEN '4000-'
WHEN T.SALARY < 5000 THEN '5000-'
ELSE
'5000+'
END ) LEVEL
FROM HR.EMPLOYEES T;